半導體產業發展六十年,每個時代都有自己的「北極星指標」。在何庭波提出 τ 縮放理論之前,行業至少先後或同時經歷了四條主要的技術路線圖。它們分別在不同的領域,找準一個參數作為縮放的目標,盡可能地去擠出海綿中的每一滴水。
一、摩爾定律與 Dennard 縮放:尺寸即算力
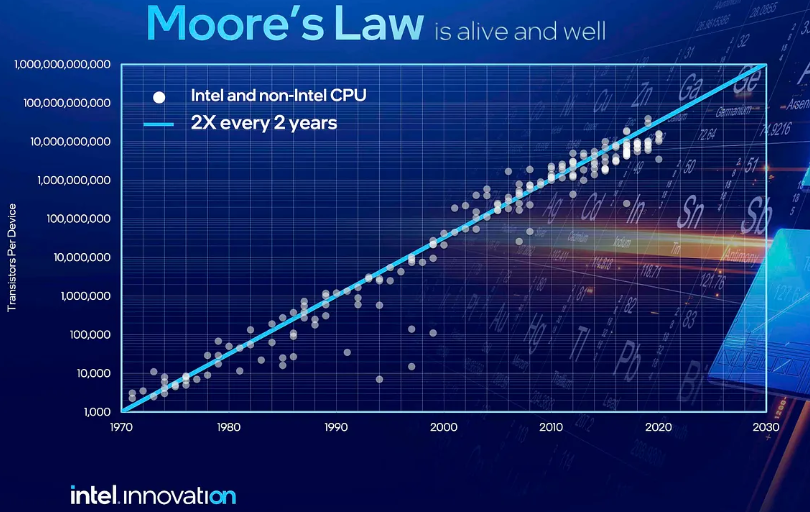
一切的起點是摩爾定律。1965 年,仙童半導體的研究總監 Gordon Moore 在《Electronics》雜誌上發表了一篇文章 "Cramming More Components onto Integrated Circuits",觀察到積體電路中單位元器件的成本會隨集成度提高而下降。他做出了一個大膽的外推:
「單位面積上的元器件數量,大約每年翻一倍。」——1965 年版本
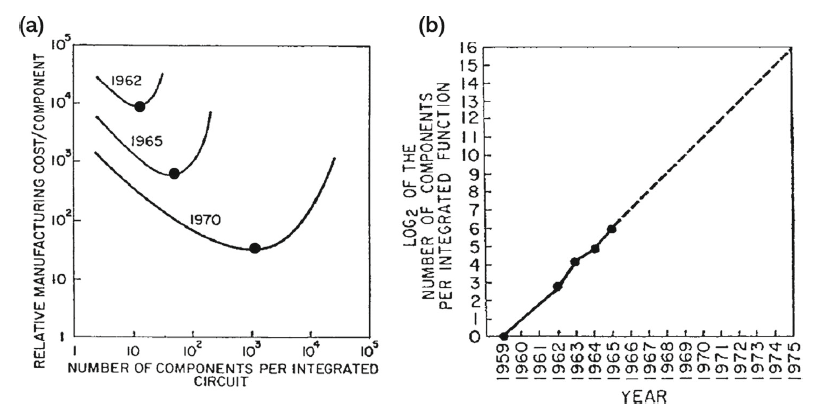
十年後的 1975 年 IEEE IEDM 會議上,他更新了數據並修正了預測。他把增長拆解為三個驅動力:晶片面積增大、元器件尺寸縮小、以及 "circuit and device cleverness"——電路設計的巧思。前兩個是為了增加單片晶片上的電晶體數量,而第三點則是提升其相互作用的效率。但他也意識到,CCD 儲存器這樣的結構已經把元器件排列得不能再緊湊了,未來主要只能靠前兩個因素,因此調整為:
「不再是每年翻一倍,而是接近於每兩年翻一倍。」——1975 年版本
到 1995 年,Moore 給出了一個更寬泛的定義:「摩爾定律已經擴展到幾乎所有半導體產業相關的、在半對數坐標上近似一條直線的事物。」這個定義揭示了摩爾定律的本質——它不是物理定律,而是產業節奏。整個產業鏈圍繞著「每兩年密度翻一倍」這個節奏來規劃研發、投資和產品迭代。
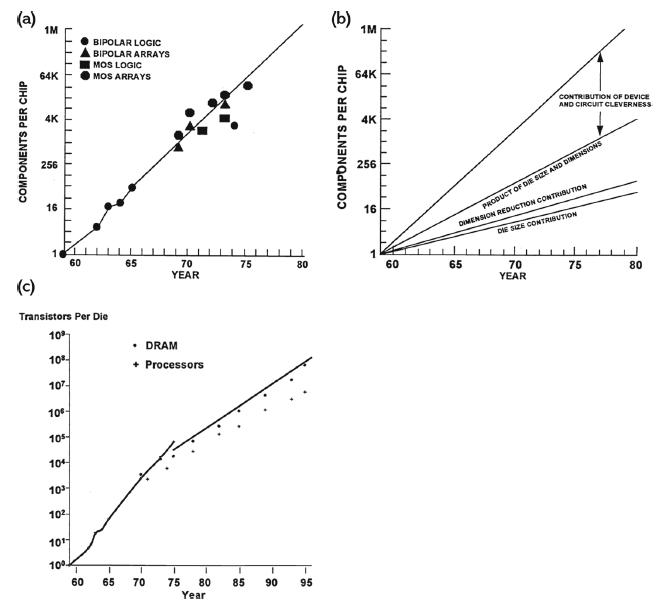
但密度翻倍本身不是目的,算力提升才是。在早期,密度和算力幾乎可以畫等號:更多的電晶體 = 更強的計算能力。這個等式的成立,其實是基於與電晶體尺寸微縮相匹配的其它參數的對應微縮來實現的,也就是 Dennard 縮放定律。Robert Dennard 是 IBM 的研究員,也是 DRAM 儲存器的發明人。1974 年,Dennard 提出:當電晶體尺寸縮小時,如果電壓和電流等比例縮小,功率密度將保持不變。也就是說,你可以把電晶體做得更小、更快、更省電——三者同時實現。這是一個完美的正循環:尺寸縮小 → 密度提高(摩爾定律);電壓等比縮小 → 功率密度不變(Dennard 縮放);閘延遲降低 → 速度提升。
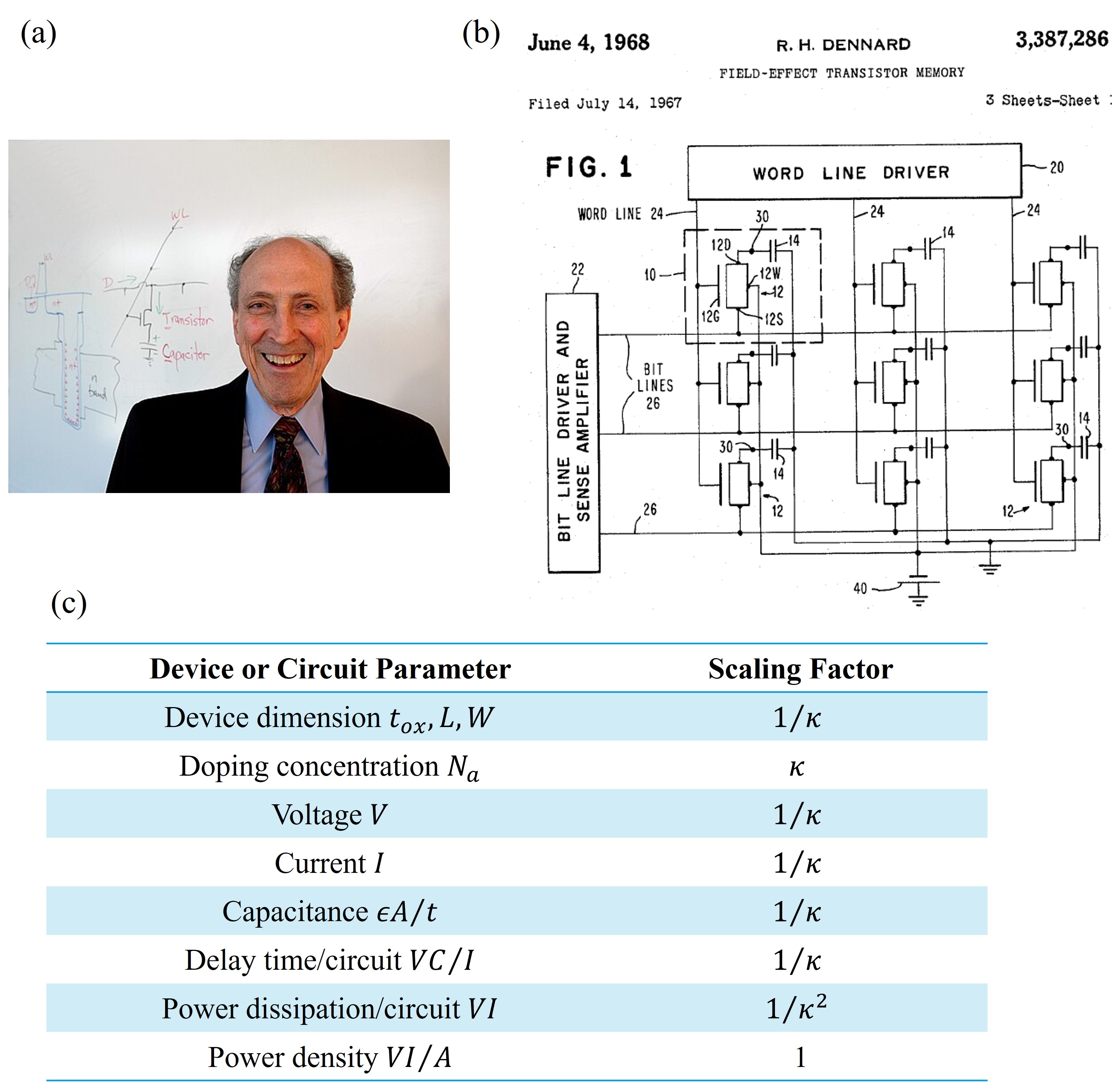
在 Dennard 縮放有效的年代,摩爾定律不僅是密度定律,實質上也是性能定律。每一代新技術節點,晶片同時變得更密、更快、更省電。這是半導體產業的黃金時代。

FinFET 的出現意味著 Dennard 縮放的終結。事實上,從 32nm 的平面 CMOS 到 22nm 的 FinFET,線寬並沒有顯著的縮小。真正的優勢提升在於可靠性的提升,而 nm 這個數字也已經不代表任何一個具體的物理寬度,而只是作為技術節點和產品更新換代的名稱。FinFET 結構引入了一些新的參數:MP、CPP、Cell Height,這些都可以作為縮放的指標。
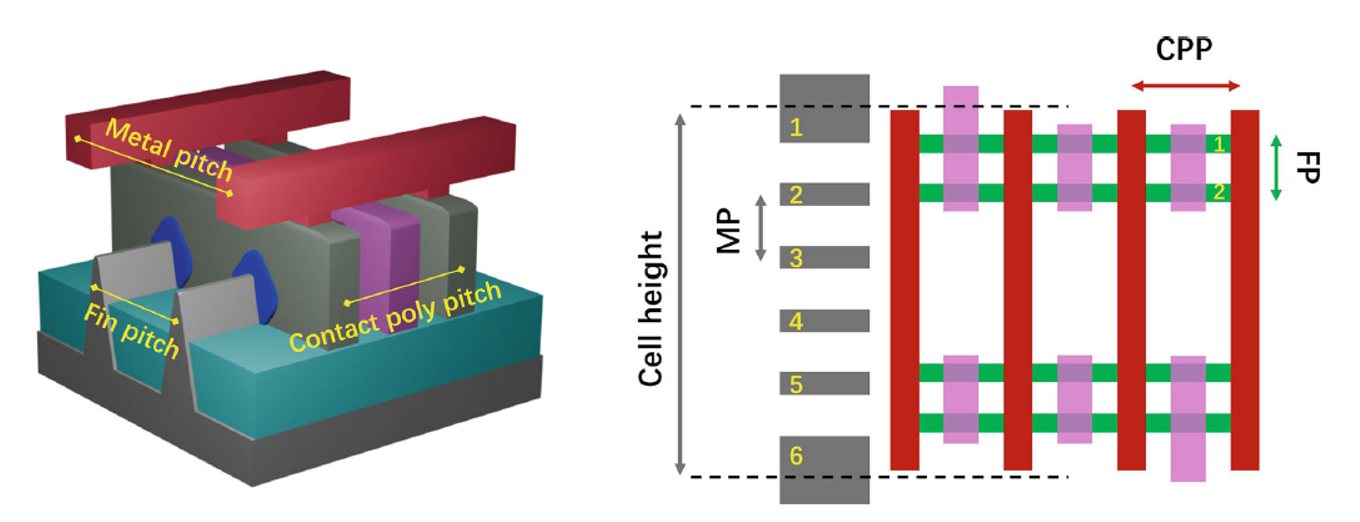
總體來看,仍然可以實現電晶體數目的「一條線」上升(指數坐標)。
二、光刻路線圖:尺寸縮減的執行者
摩爾定律和 Dennard 縮放定義了「要做什麼」——把電晶體做得更小。而光刻則回答了「怎麼做到」。
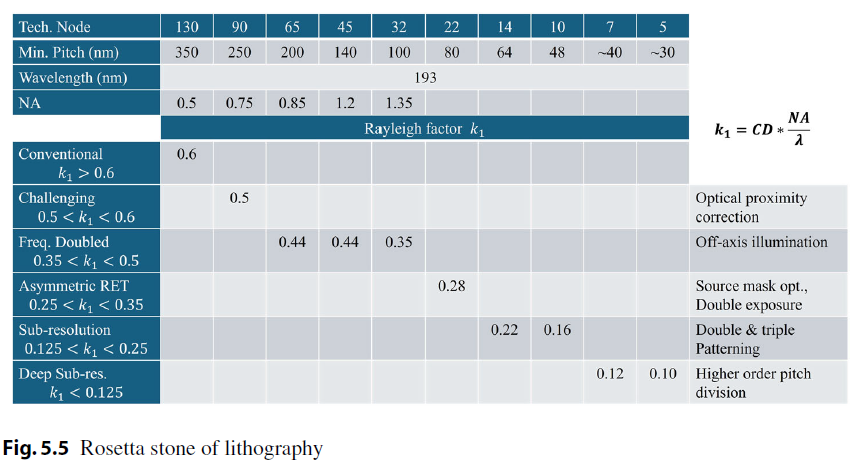
光刻的分辨率遵循瑞利公式:
CD = k₁ × λ / NA
其中 CD 是最小可分辨特徵尺寸,λ 是光源波長,NA 是數值孔徑,k₁ 是工藝因子。要把 CD 做小,有且僅有三條路:縮短波長、增大 NA、降低 k₁。
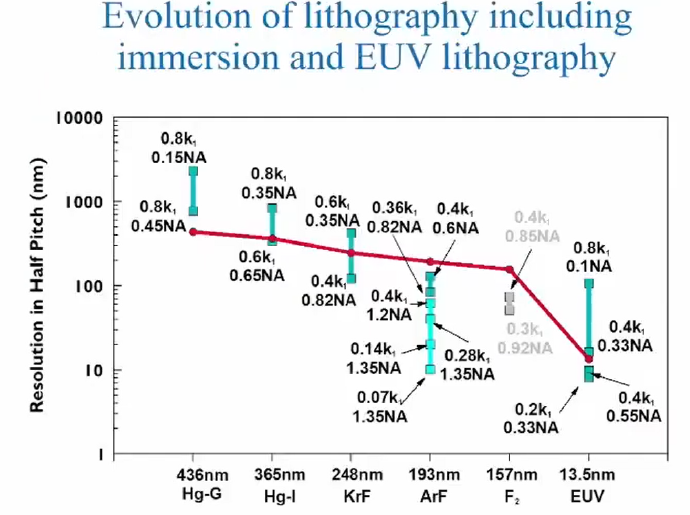
縮短波長(λ↓)
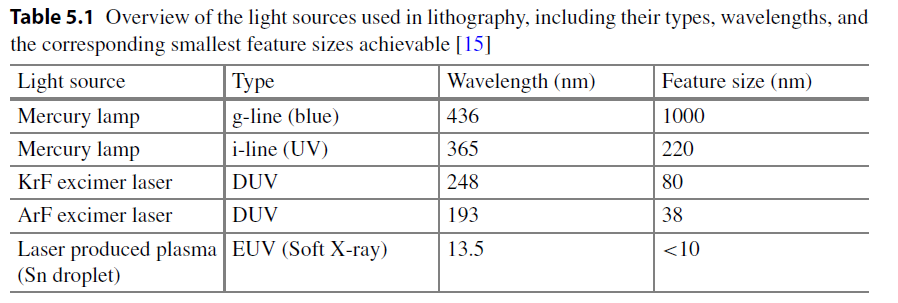
最直接的路徑。光源從 g-line(436 nm)演進到 i-line(365 nm),再到 KrF 準分子雷射(248 nm)和 ArF(193 nm),每一次波長的跳變都打開了新一代節點的大門。最終,EUV(13.5 nm)的實現——波長一步縮短了 14 倍——徹底改變了遊戲規則,使 7nm 及以下節點成為可能。
增大 NA
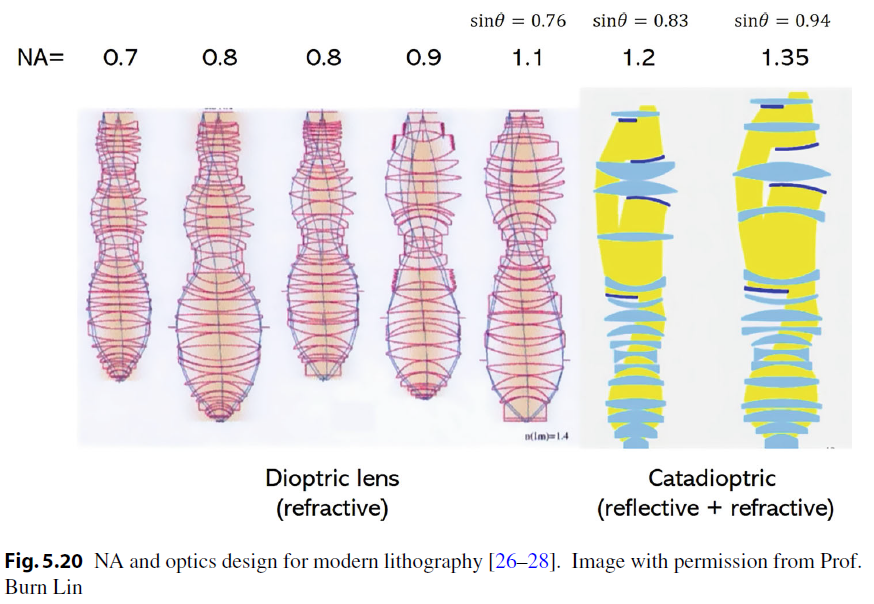
NA 數值孔徑,其實體現的是鏡頭收光的角度,因此複雜而龐大的鏡頭組合被製造出來從而盡可能增大收光角度。傳統乾式光刻的 NA 上限約為 1.0(受限於空氣中光的折射)。2004 年,林本堅提出了浸潤式光刻的概念——在鏡頭與晶圓之間注入高折射率液體(水),將 NA 推升至 1.35。這一突破延長了 193nm ArF 光源的生命至少三代節點,被認為是光刻歷史上最重要的工程創新之一。當然,如果把折射率 1.35 放到等式的分子位置上,也可以理解成其降低了有效波長。進入 EUV 時代後,我們將無法使用透鏡,因為鏡頭材料對 EUV 的吸收率很高,因此只能換成反射鏡。如今,ASML 的 High-NA EUV 工具進一步將 NA 從 0.33 提升至 0.55,為 2nm 及以下節點鋪路。
降低 k₁(RET 技術)
通過分辨率增強技術(RET),如光學鄰近校正(OPC)、離軸照明(OAI)、相移掩模(PSM)以及多重圖案化(multiple patterning),工程師們把 k₁ 從理論極限 0.25 不斷逼近,在不改變光源和鏡頭的前提下榨取更多分辨率。三條路徑共同推進,光刻成為了摩爾定律最忠實的執行者。但這條路也越來越貴——一台 High-NA EUV 光刻機的價格已超過 4 億美元。
三、先進封裝路線圖:跳出單片,追逐系統級密度
摩爾定律的本質是經濟學規律,更多的電晶體集成到晶片上,是為了降低實現同等算力的成本。但是當特徵尺寸達到特定的節點之後,繼續縮減尺寸,反而會導致單一電晶體成本的上升(考慮到昂貴的光刻機台、複雜的蝕刻製程等),而在材料創新所帶來的優勢也有限的情況下,通過先進封裝的方式來實現的異質集成,則是一條必由之路。
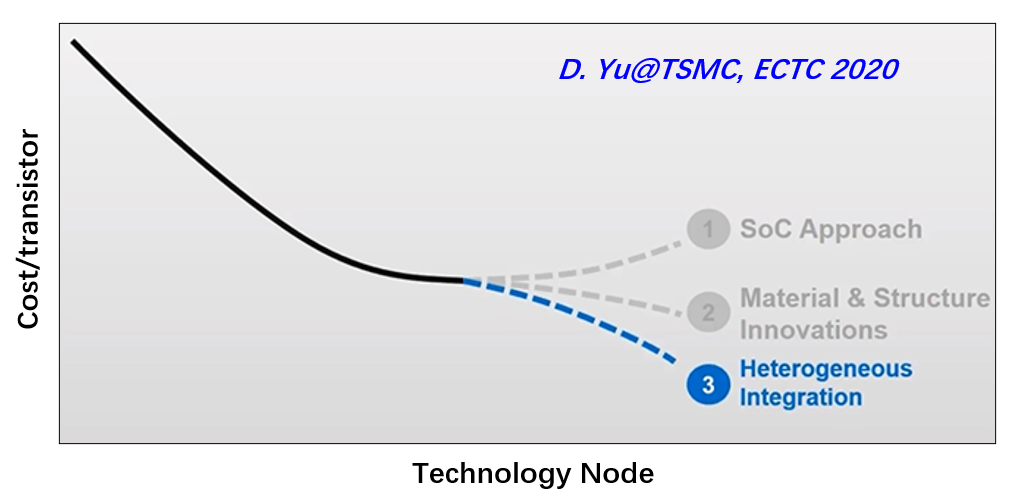
這就是 TSMC 先進封裝路線圖的核心邏輯——從單片密度跳向系統級密度。
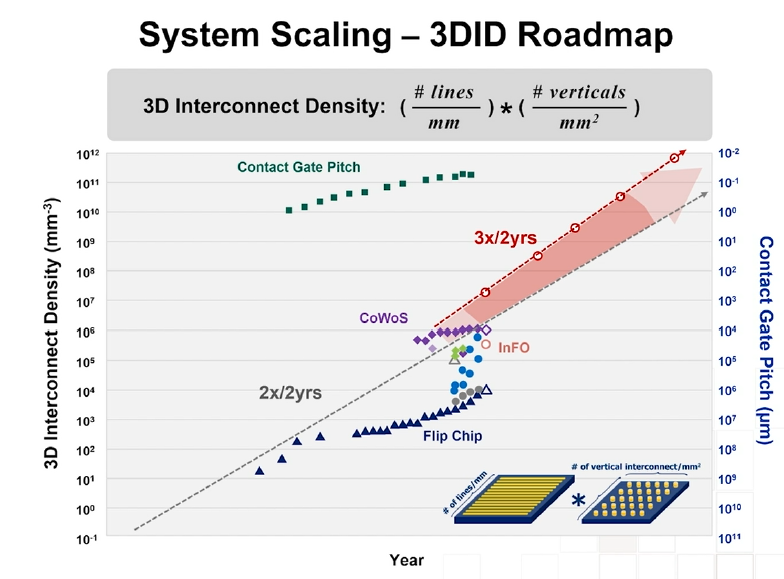
傳統封裝(如引線鍵合)只是把晶片連接到外部世界,技術門檻和利潤率都不高,因此台積電在早期並不把封裝作為公司的主營業務。多晶片互連原本是在封裝的層面上完成,但如果使用晶圓作為中介板,則可以實現傳統載板無法實現的線寬和互連密度,在這個思考上,就有了 CoWoS。早些年,台積電拒絕了 IBM 的方案,在 0.13μm 製程上自行開發出了 on-chip interconnect 的技術,而將這些技術復刻到 off-chip interconnect 上,就有了 CoWoS。後來則逐步發展出了 InFo、SoIC 等先進封裝方案,最終形成了 3D-Fabric 晶圓級系統整合平台。
TSMC 展示了三代先進封裝技術的演進:
2.5D CoWoS(Chip-on-Wafer-on-Substrate):通過矽中介層將多顆晶片並排放置,利用矽通孔(TSV)和微凸塊實現高密度互連。這是 NVIDIA H100/H200 GPU 的核心封裝方案,也是 AI 算力爆發的物理基礎。
InFO(Integrated Fan-Out):取消傳統基板,直接在晶圓級完成扇出型封裝,縮短互連路徑,降低功耗。蘋果 A 系列晶片率先採用。
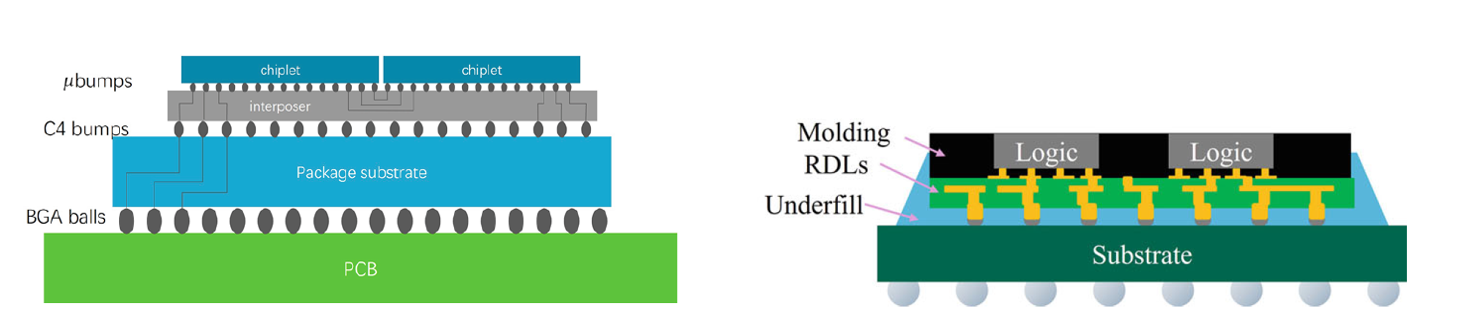
SoIC(System-on-Integrated-Chips):真正的 3D 堆疊——晶片面對面直接鍵合,實現亞微米級的垂直互連密度。並且,SoIC 可以分別和 CoWoS 和 InFO 結合,前段 3D 與後端 3D 的結合。
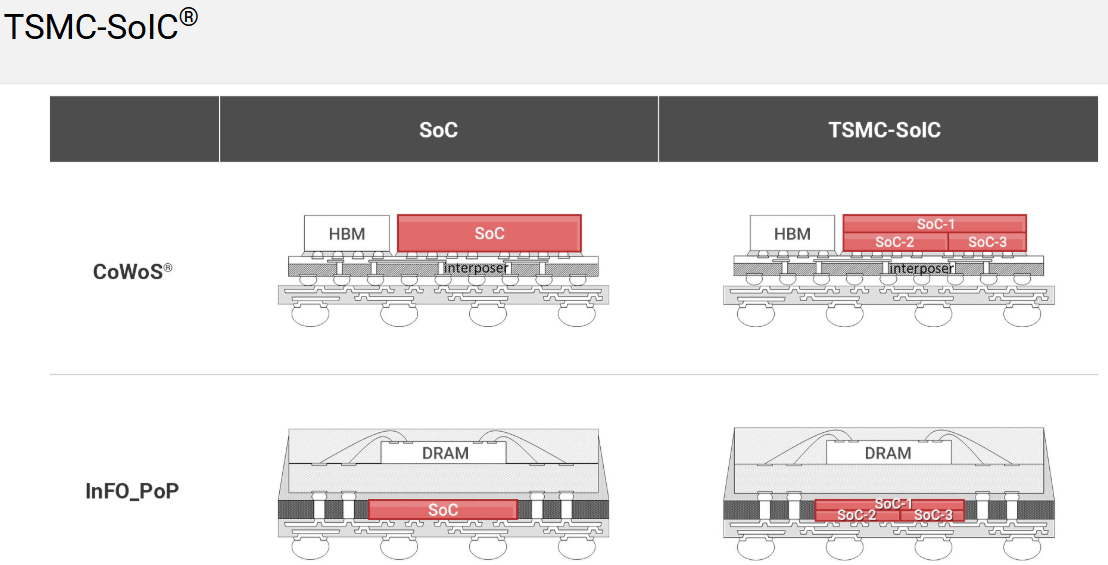
通過這些技術的組合,3D 互連密度可以實現大約每兩年 3 倍的增長速率。封裝從幕後走向台前,成為延續摩爾定律的關鍵使能技術。這條路線圖的北極星指標不再是單顆晶片上有多少電晶體,而是整個系統中單位體積內有多少有效互連——一個全新的維度。
四、互連路線圖:第一個以 τ 為指標的領域
如果說封裝從空間維度找到了新的增長方向,那麼互連則更早一步提出了一個根本性的問題:密度再高,如果信號傳不過去,有什麼用?
事實上,互連(Interconnect)是半導體五大領域中,第一個真正以時間延遲 τ 作為路線圖核心指標的領域。
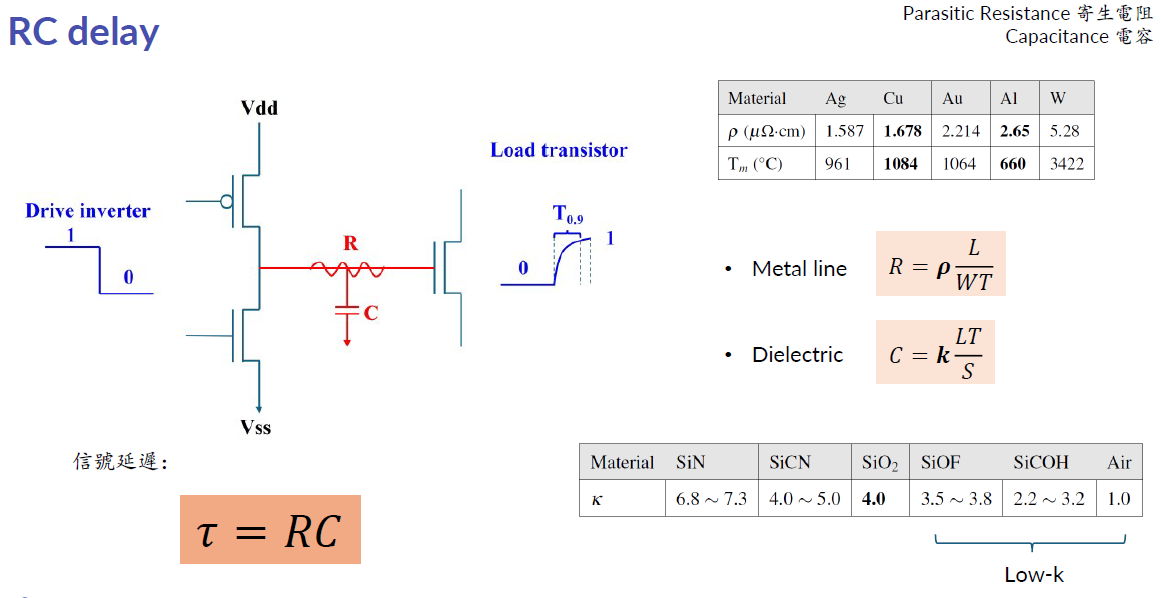
互連的延遲由一個簡單而深刻的公式決定:
τ = R × C
其中 R 是導線電阻,C 是線間電容。要降低 τ,要麼降 R,要麼降 C。整條互連路線圖的歷史,就是圍繞這兩個字母展開的工程史詩。
降 R:從鋁到銅,以及 "Better than Cu"
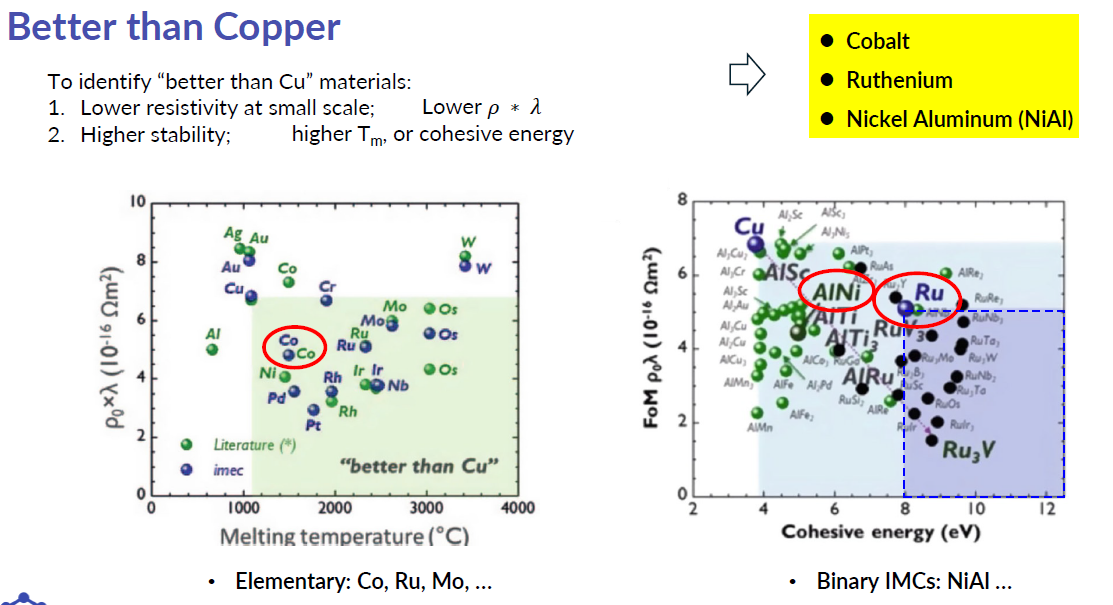
在 1997 年之前,互連材料用的是鋁(Al)。但隨著線寬縮小,鋁的電阻率成為性能瓶頸。1997 年,IBM 率先將銅(Cu)引入積體電路互連——銅的電阻率只有鋁的約 60%。這是互連領域最重要的材料革命。
但到了 5nm 以下節點,銅也遇到了麻煩。當線寬小於銅的電子平均自由程(約 39nm),電子散射急劇增加,電阻率飆升——這就是所謂的尺寸效應。行業開始尋找 "Better than Cu" 的替代方案:鈷(Co)已在某些局部互連中使用;釕(Ru)因其更短的電子平均自由程(約 6.7nm)在極細線寬下展現出優勢;鎳鋁(NiAl)等有序金屬間化合物也在研究之中。
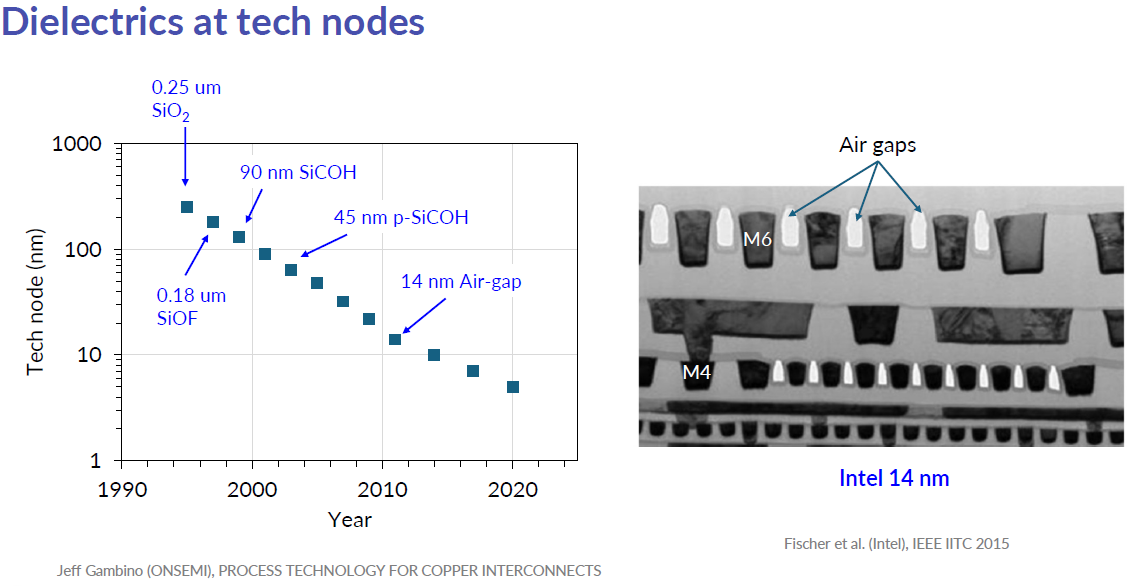
降 C:從 SiO₂ 到 low-k 到 air gap
電容方面,傳統的 SiO₂ 介質介電常數約為 4.0,後來逐步替換為碳摻雜氧化物(SiOCH)等低介電常數(low-k)材料,k 值降至 2.5–3.0。進一步的方案是引入氣隙(air gap)——空氣的介電常數接近 1.0,是終極的 low-k 材料。
為什麼互連率先使用 τ?
原因很直觀。對電晶體來說,縮小尺寸在 Dennard 縮放有效時同時帶來了更高的速度和更低的功耗——性能提升是「免費」的,不需要單獨追蹤時間指標。但對互連來說恰恰相反:線越細,R 越大;線越密,C 越大。尺寸縮小不僅不會自動提升性能,反而會惡化延遲。
這種與電晶體截然相反的縮放行為,迫使互連領域從一開始就直面時間延遲問題,把 τ = RC 作為路線圖的核心度量。圍繞 R 和 C 的材料創新——銅替鋁、low-k 替 SiO₂、氣隙——本質上都是在與 τ 作戰。
五、從互連的 τ 到系統的 τ
回顧這四條路線圖,可以看到一條清晰的演進脈絡:
- 摩爾定律 + Dennard 縮放 → 追求電晶體密度,密度 ≈ 算力(黃金時代)
- 光刻路線圖 → 實現尺寸縮減的工程手段(波長↓ NA↑ k₁↓)
- 先進封裝路線圖 → 單片密度增長放緩後,轉向系統級密度
- 互連路線圖 → 第一個以 τ(時間延遲)為北極星指標的領域
每一步都是對前一步瓶頸的回應。而當我們把視野從單個領域拉高到整個系統——晶片內部的電晶體延遲、互連延遲、晶片間的封裝延遲、協議轉換的延遲——就會發現:這些「時間稅」正在成為制約系統性能的主導因素。互連領域的 τ = RC,只是冰山一角。整個半導體系統需要一個統一的、以時間為核心的優化框架。這正是 τ 縮放理論登場的起點。
六、華為 τ 定律的解讀
如果把摩爾定律對終端用戶的價值還原到本質,它其實從來不只是關於「幾何尺寸」的故事。用戶並不關心電晶體到底有幾奈米,真正關心的是手機響應快不快,程式運行快不快,AI 推理快不快。更小的電晶體之所以有價值,是因為它們開關更快;更密集的互連之所以有價值,是因為信號傳播距離更短;更高的集成度之所以有價值,是因為數據少跨一次晶片、少穿一層協議、少繞一段遠路。換句話說,摩爾時代表面上是在縮小空間,實質上是在壓縮時間。
τ 縮放,試圖作為幾何摩爾縮放之後的新一代縮放原則,用「時間」而不是單純的「空間」來衡量電子系統的進步。形式上,τ 可以被看作一個分層結構:
τ = f(τtransistor, τcircuit, τchip, τsystem)
其中 τtransistor 表示電晶體層面的時間常數,τcircuit 表示電路層面的時間常數,τchip 表示晶片層面的時間常數,τsystem 表示系統層面的時間常數。
這幾個量不是彼此割裂的。每一層的 τ 都由下層 τ 以及本層新引入的組織開銷、通信開銷共同組成。也就是說,電晶體變快了,不代表晶片一定等比例變快;晶片峰值提高了,也不代表系統一定等比例變快。中間每一層都會「收稅」:互連要收稅,快取要收稅,協議棧要收稅,同步機制也要收稅。τ 縮放要做的,就是把這些時間稅一層層算清楚,再一層層壓下去。

τ 的尺度跨度非常大。它在時間上大約跨越十二個數量級,從皮秒到秒;在空間上也跨越極大範圍,從奈米級電晶體,到公里級數據中心。也正因為跨度如此之大,不同層面的 τ 需要用不同方法來降低:在電晶體層,核心問題是本徵開關延遲;在電路層,核心問題是信號路徑上的 RC 傳播延遲;在晶片層,核心問題是計算和記憶體存取延遲;在系統層,核心問題是端到端訊息傳遞和同步時間。
從這一分層結構出發,可以得到一個代際規則:
τn+1 = τn / α
這裡的 α 是縮放因子,表示下一代系統相對上一代系統能夠把 τ 壓縮多少。需要強調的是,α 不再是一個放之四海皆準的常數,而是與應用場景有關。對功耗受限的移動設備來說,能效、散熱、面積和電池壽命都很敏感,量產經驗顯示,α 大約可以達到每年 1.3×。對安全關鍵型自動系統來說,確定性、可靠性和即時響應更加重要,α 大約可以達到每年 1.5×。而對 AI 工作負載來說,吞吐量能夠直接轉化為訓練效率、推理成本和商業價值,因此在某些階段,系統級 α 最高可以達到每年 10×。
這裡說的 10×,並不是說電晶體一年快十倍,而是說 AI 系統中的主導瓶頸可能被架構、互連、儲存、封裝和軟體協同顯著壓縮。比如,少一次跨機通信,減少一層協議棧,縮短一次同步等待,都可能比單純提升某個計算單元頻率更有價值。
這也解釋了為什麼 τ 能成為一個真正有用的主指標,而不是給舊概念換個名字。頻率、延遲、頻寬和吞吐量,看起來是不同指標,但本質上都和時間有關。頻率是單位時間內能做多少事,延遲是完成一件事要等多久,頻寬是單位時間內能搬多少數據,吞吐量是單位時間內能完成多少任務。它們都可以放回 τ 的框架中討論。
除各層級的時間優化以外,計算和儲存的再融合是另一個重要的走向。回到 8086 的時代,處理器和記憶體是有意被解耦的。CPU 負責計算,DRAM 負責儲存,中間通過標準化記憶體匯流排連接。這個設計在當時極其成功——它把複雜系統拆成了兩個可以獨立演進的產業:處理器廠商沿著摩爾曲線提高性能,儲存器廠商沿著容量、成本和頻寬曲線發展自己的市場。計算和儲存像兩座相鄰城市,中間有一條足夠便宜、足夠穩定的公路。只要這條公路還能承載流量,分工就是合理的。
但 AI 時代正在反轉這條路。原因很簡單:那條連接計算和儲存的「公路」,越來越堵,也越來越貴。在傳統計算中,很多程式的工作集較小,快取層級可以擋住相當多的記憶體存取壓力;但在大模型訓練和推理中,參數、啟動值、KV Cache、梯度、專家路由和中間狀態都在快速膨脹。計算單元越來越密,矩陣乘陣列越來越強,晶片峰值算力越來越高,但數據如果不能及時送到,計算單元就只能等待。數據移動已經和計算本身同等重要,甚至在很多場景中比計算更重要。HBM 的興起,就是這個趨勢的直接結果。HBM 把多層 DRAM 堆疊起來,通過中介層或先進封裝貼近邏輯晶片,目的不是形式上更高級,而是為了用更短距離、更寬介面提供更高頻寬。混合鍵合也是如此,它進一步拉近邏輯與儲存之間的物理距離,讓數據不必繞遠路。3D 堆疊 SRAM 同樣指向這個方向:把高速片上儲存做得更近、更密、更立體,讓關鍵數據盡量留在計算附近。
過去,先進邏輯節點往往站在產業敘事的中心。誰能做出更先進的 CPU、GPU、NPU,誰就掌握主要話語權。未來,儲存和封裝的重要性會顯著上升。HBM 供應能力、先進封裝產能、混合鍵合良率、3D SRAM 技術、光 I/O 集成能力,都會成為系統競爭力的一部分。AI 硬體時代的贏家,不會只是擁有最強邏輯晶片的一方,也會是能夠把邏輯、儲存、封裝和互連組織成一個高效整體的一方。
這也帶來一個產業問題:技術上可以融合,經濟上如何分配收益?τ 縮放在這裡提供了一把帳本。它把每一次分離的代價都量出來:一次跨封裝存取要多少時間,一次遠端記憶體存取要多少能量,一層協議轉換要多少延遲,一個額外 buffer 要多少面積和功耗。過去這些代價可能被隱藏在系統複雜性裡,今天則必須被攤開計算。只要這些跨層成本變得可見,邏輯與儲存的重新融合就不再是一個可有可無的技術方向,而是 AI 時代無法迴避的結構性趨勢。
數據在哪裡,計算應該離它多近?
參考資料:"Insights into Semiconductor Technologies," Springer Nature;知乎:多層電子系統的時間縮放理論 - 何氏定理(作者:何庭波 - 海思)。本文僅供技術交流,不構成投資建議。